1. RNN이란?
“순경 신경망” 으로 시계열 데이터나 순차적인 데이터 처리에 특화된 신경망 구조 입니다.
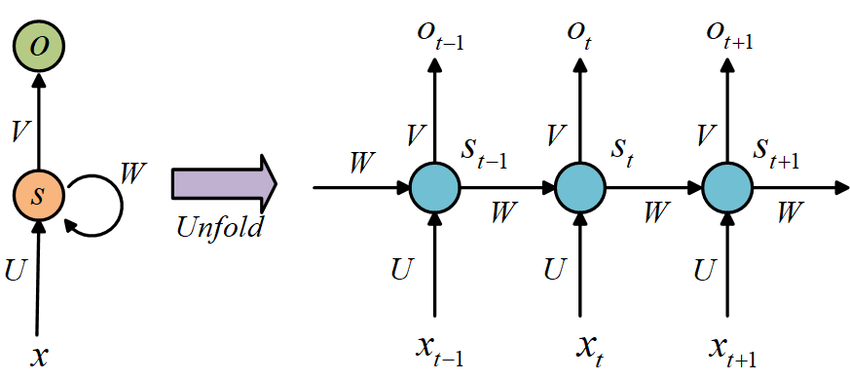
이 복잡한 모델이 어떻게 작동하는지 차근차근 알아봅시다.
유명한 데이터셋 중에 네이버 영화 리뷰 데이터 셋이 있습니다.
리뷰를 보고 영화에 긍정적인지 부정적인지를 판단하는 문제입니다.
“기대 안하고 보면 의외로 긴장감있고 괜찮음” => 긍정 or 부정위 예시를 통해 RNN이 리뷰를 긍정인지 부정인지를 예측하는 과정을 함께 살펴봅시다.
2. 토큰
일단 문장을 토큰 단위로 자릅니다.
"기대 안하고 보면 의외로 긴장감있고 괜찮음"
-> ['기대', '안', '하다', '보다', '의외이다', '긴장감', '있다', '괜찮다']토큰 자른 예시는 조금더 이해하기 쉽게 표제어 추출 전처리 한 단어 단위로 자른 것입니다.
실제로 토큰화 방법에 대해서는 불용어 제거, 어간 추출, 표제어 추출, 정규화, 형태소 분석, BPE, wordPiece 등 기법을 배워야 합니다.
3. Vocab 만들기
토큰으로 잘랐으면 모든 토큰을 모아서 숫자를 부여해 줍니다.
원래는 다른 문장들도 있어서 엄청나게 많은 토큰들이 있겠지만 편의상 한 문장만 있다고 가정하고 Vocab을 만들겠습니다.
vocab = {
0 : '기대',
1 : '안',
2 : '하다',
3 : '보다',
4 : '의외이다',
5 : '긴장감',
6 : '있다',
7 : '괜찮다'
}그러면 자연스럽게 문장을 숫자로 나타낼 수 있습니다.
"기대 안하고 보면 의외로 긴장감있고 괜찮음"
-> ['기대', '안', '하다', '보다', '의외이다', '긴장감', '있다', '괜찮다']
-> [0, 1, 2, 3, 4, 5, 6, 7]이를 정수 인코딩 또는 단어-정수 매핑 이라고 합니다.
4. 원-핫 인코딩 표현
총 vocab이 8개 있으니 8차원 원-핫 인코딩으로 표현 할 수 있습니다.
vocab = {
[1, 0, 0, 0, 0, 0, 0, 0] : '기대',
[0, 1, 0, 0, 0, 0, 0, 0] : '안',
[0, 0, 1, 0, 0, 0, 0, 0] : '하다',
[0, 0, 0, 1, 0, 0, 0, 0] : '보다',
[0, 0, 0, 0, 1, 0, 0, 0] : '의외이다',
[0, 0, 0, 0, 0, 1, 0, 0] : '긴장감',
[0, 0, 0, 0, 0, 0, 1, 0] : '있다',
[0, 0, 0, 0, 0, 0, 0, 1]: '괜찮다'
}최종적으로 문장을 원-핫 인코딩으로 표현 할 수 있습니다.
"기대 안하고 보면 의외로 긴장감있고 괜찮음"
-> ['기대', '안', '하다', '보다', '의외이다', '긴장감', '있다', '괜찮다']
-> [0, 1, 2, 3, 4, 5, 6, 7]
-> [[1, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 1],
] 5. RNN모델 입력
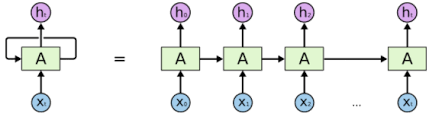
위 머리 아픈 그림이 실제 RNN을 잘 도식화 해놓은 그림입니다.
저희 예시에 대입해 보면 아래와 같이 됩니다.
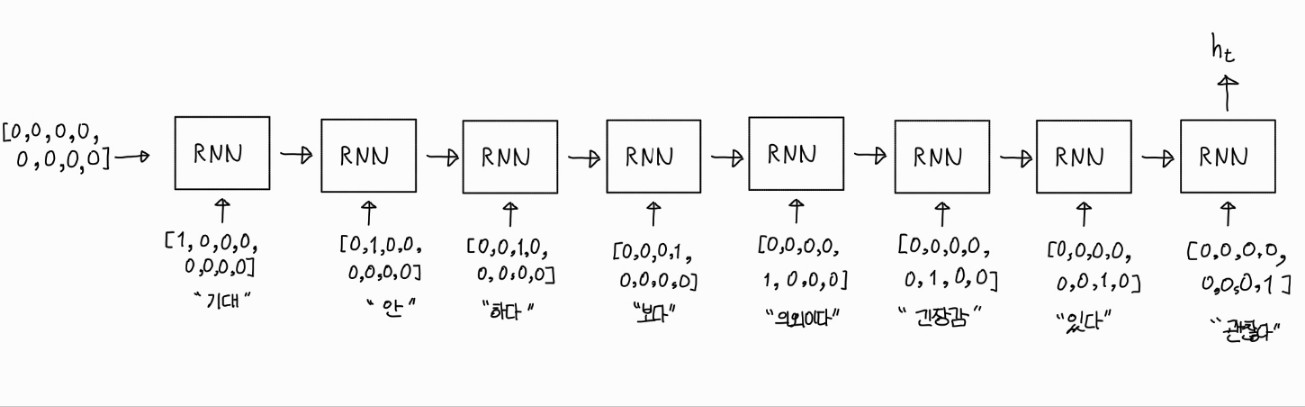
모든 RNN모델에는 2개의 입력이 들어가는 것입니다.
하나는 원-핫 인코딩으로 표현한 토큰이 들어가고
다른 하나는 이전 RNN의 계산 결과 값이 들어갑니다.
참고로 처음 [0, 0, 0, 0, 0, 0, 0, 0] 은 초기화 방법에 따라 [1, 1, 1, 1, 1, 1, 1, 1]을 넣어 줄 수 도 있습니다.
그러나 일반적으로 모든 값이 0인 zero-initialize를 대체로 사용합니다.
6. RNN모델 ht 계산

RNN에 모델에 입력된 토큰과 이전 RNN결과 값이 모델안에서 어떻게 사용되는지 알아봅시다.
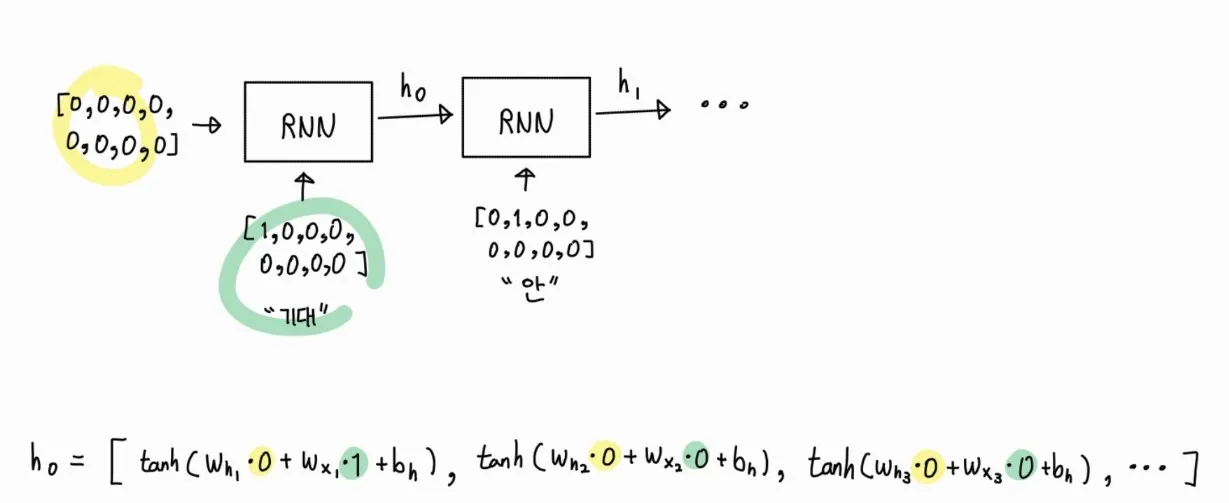
RNN이 출력하는 ht의 값 중 첫 번째 값인 h0에 대한 계산 방법 입니다.
여기서 Wh, Wx, bh 라는 변수가 사용되는데 이 값들이 바로 학습되어야 할 대상입니다!
처음은 학습이 안되어 있으니 랜덤한 값으로 초기화 되어있습니다.
(일반적으로 Xavier 초기화, He초기화 방법 많이 사용하지만 설명에서는 랜덤 초기화 사용할게요…)
저희는 예시로 초기값을 아래와 같이 랜덤하게 잡아봅시다.
Wh = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]
Wx = [0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1]
bh = 0.1위 값을 대입하여 h0을 구해봅시다.

tanh(0.9) = 0.7163, tanh(0.1) = 0.0997 이므로
h0 = [0.7163, 0.0997, 0.0997, 0.0997, 0.0997, 0.0997, 0.0997, 0.0997] 이 됩니다.
해당 값은 첫번째 RNN의 결과 값으로 다음 RNN의 입력으로 사용됩니다.
h1도 계산해 봅시다.
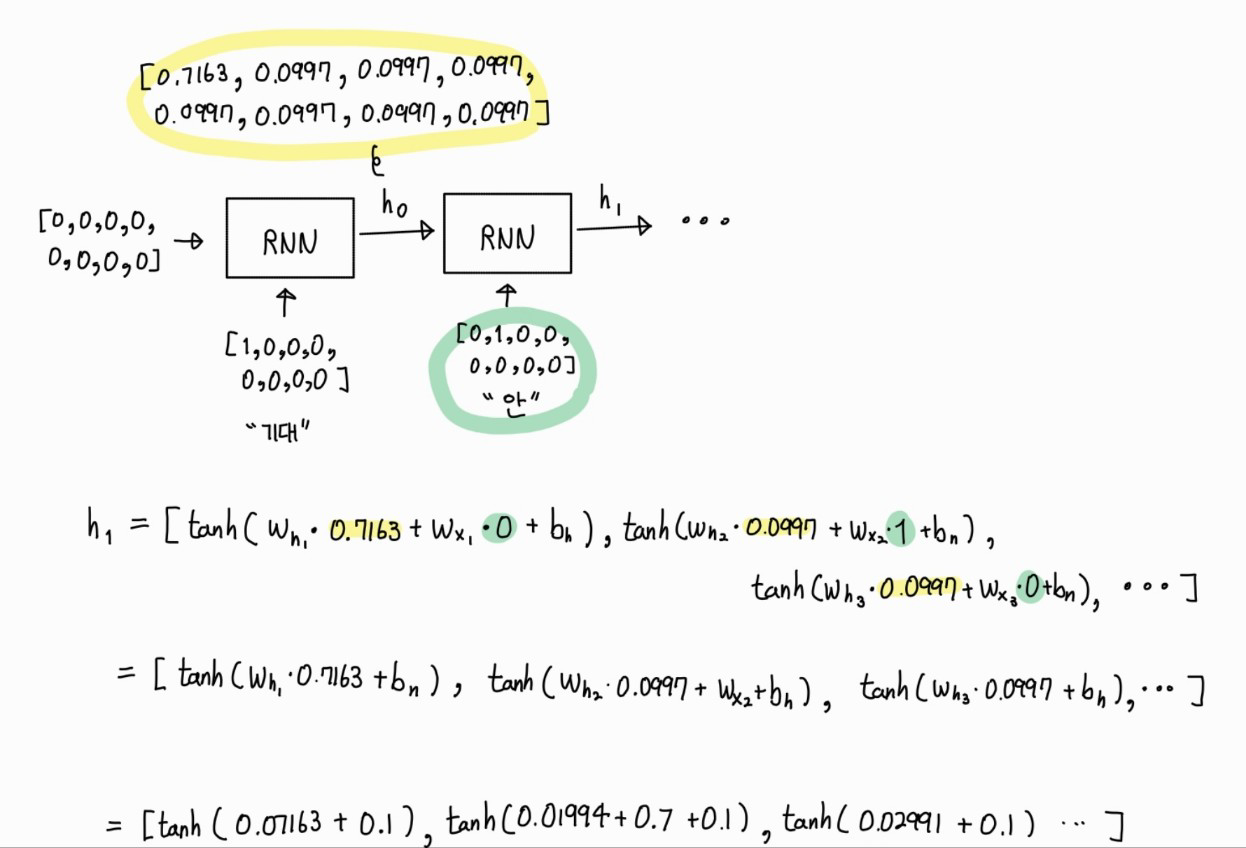
h0을 구했던 과정과 동일한 계산 과정입니다.
단지 ht-1 값이 [0, 0, 0, 0, 0, 0, 0, 0] 이 아니라 “기대”토큰과 [0, 0, 0, 0, 0, 0, 0, 0]이 RNN의 입력으로 들어가 결과로 반환 받은 [0.7163, 0.0997, 0.0997, 0.0997, 0.0997, 0.0997, 0.0997, 0.0997] 입니다.
이렇게 연쇄적으로 계산되어 마지막 토큰까지 계산 됩니다.
계산 결과 h8 ≈ [0.2908, 0.3790, 0.4608, 0.5355, 0.6026, 0.6622, 0.7144, 0.7597] 이 됩니다.
7. RNN 모델 yt 계산
모델의 출력값 yt가 어떻게 구해지는지 알아봅시다.

h8 각 값에 Wy를 곱하고 bh를 더합니다.
Wy와 bh도 Wx, Wh 와 같이 랜덤으로 초기화 됩니다.
예시로 아래와 같은 값을 가졌다고 하고 계산해 보겠습니다.
# 랜덤으로 초기화 된 가중치와 bias
Wy = [1, 0.2, 0.3, -0.21, 0.3, 0.12, -0.1, 1.2]
by = 0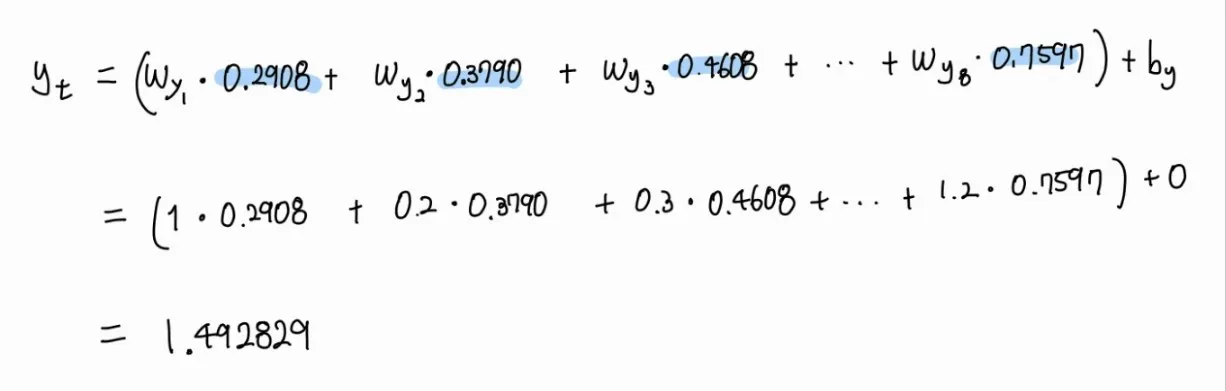
그 결과 yt 값이 1.492829가 나옵니다.
8. 확률 계산

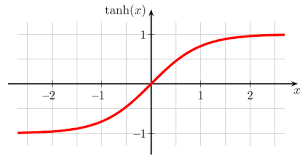
해당 yt를 sigmoid 함수에 넣습니다.
시그모이드 함수는 값이 크면 클 수록 1에 가깝게 값이 작으면 작을 수록 0에 가깝게 반환합니다.
실제 모델의 출력값(yt) 1.492829를 시그모이드에 넣으면 0.81643이 나옵니다.

즉 RNN이 볼 때 "기대 안하고 보면 의외로 긴장감있고 괜찮음" 라는 문장이 81.643% 확률로 긍정 이라고 판단한 것 입니다.
9. 학습
솔직히 첫 번째에 맞춘것은 뽀록 입니다.
왜냐하면 Wh, Wx, Wy, bh 들이 모두 랜덤 값이 었습니다.
만약 다른 랜덤값으로 할당 받았으면 해당 문장을 부정이라고 판단 할 수 있을 것입니다.
따라서 우리는 Wh, Wx, Wy, bh 값을 “기대 안하고 보면 의외로 긴장감있고 괜찮음” 이라는 입력이 오면 긍정으로 계산 할 수 있도록 업데이트 합니다.
이 과정은 역전파 라는 수학적 계산에 의해 일어납니다.
이미 여기까지 이해한 여러분이 대단하니 역전파는 다음에 따로 이해해 봅시다.
역전파 과정을 통해 Wh, Wx, Wy, bh, by 값이 변한다는 것만 기억해주세요.