1. 딥시크 란?
중국에서 개발한 인공지능 모델로 획기적인 학습 방식을 활용하여 저렴한 GPU에서 학습했지만 성능은 ChatGPT-4o와 비슷하거나 몇개 부분에서 우수하다고 알려지며 25년 1월 말에 화재가 되었습니다.
쉽게 말하면 “싸지만 성능은 좋다” 라는 점과 “오픈 소스로 풀려있다” 라는 점이 딥싱크가 화두가 될 수 있었던 포인트였습니다.
화두가 된 만큼 여러 논란들이 있는데 해당 논란들을 하나씩 팩트 체크 해보자.
2. 딥시크 성능이 좋다?

💡생성형 인공지능 성능 평가 방법생성형 인공지능에 주요 평가항목은 언어능력/수학/코딩/과학 등이 있다.
각 능력을 평가할 수 있는 문제집을 만들어두고 풀게 시킨다.
이때 정답률을 확인해서 모델의 성능을 평가한다.여기서 문제집은 아무 문제집이나 푸는 것이아니라 해당 능력을 평가하기 적절하다고 증명된 문제집을 푼다. 이런 문제집을 전문용어로 밴치마크(benchmark) 라고 한다.
📌 AIME 2024 (수학)
: 미국 수학 올림피아드 문제 933개로 구성된 밴치마크. 고난도 수학 능력을 평가하는데 사용되는 밴치마크이다.
Pass@1의 의미는 1번의 추론에서 맞춘 문제의 비율을 의미한다.
📌 Codeforces (코딩)
: 실제 코딩 문제가 모여있는 사이트. 백준 문제 평가 방법과 동일하다.Percentile은 여러 모델들 중 하위 몇 %인지를 알려준다.
절대적인 점수가 아닌 다른 모델과 비교한 백분율 점수이기에 다른 모델에 비해 얼마나 뛰어난지 알기 쉽다.
📌 GPQA Diamond (과학)
Google에서 만든 물리학, 화학, 생물학 분야의 박사급 고난도 다지선다형 문제(다지선다형을 전문용어로 MCQA라고 말합니다.)로 구성된 밴치마크. 해당 분야 박사과정 학생(혹은 소지자)들도 평균 65% 정답률을 보이고 있다.
📌 MATH-500 (수학)
고등학교 및 대학 초급 수준의 수학 문제 500개로 구성된 밴치마크. 대수, 기하, 미적분, 확률 등의 문제로 구성됨.
📌 MMLU (언어)
약 1만 6000개의 광범위한 주제(인문학, 사회과학, 자연과학, 역사 등)의 MCQA 밴치마크.
언어 이해 능력과 얼마나 다양한 분야의 지식을 알고있는지를 평가할 수 있다.
생성형 AI 평가하면 무조건 하는 밴치마크.
📌 SWE-bench Verified (코딩)
Github의 12개 인기 Python 오픈소스 저장소에서 가져온 2294개의 Issue 와 해당 Issue를 해결한 pull request 쌍으로 이루어진 밴치마크(SWE-bench)에서 인간주석자가 확실이 검증한 500개의 샘플 데이터. OpenAI에서 만듦.
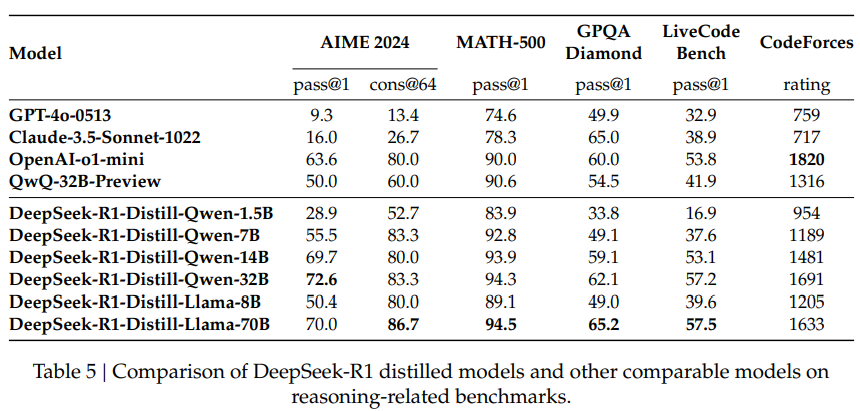
정말 놀라운 점은 Distill 모델의 성능에 있다.
Distillation은 성능 좋은 큰 모델을 작은 사이즈로 만드는 방법이다. (방법에 대해 이해하시려면 생성형 AI의 학습 방법, Loss function 등에 대한 이해가 필요합니다. 그러니 지금은 Skip)
1.5B 사이즈가 4o 성능을 앞선다는 것은 미쳤습니다.
게이밍 컴퓨터에 들어있는 GeForce RXT-4090에서 7B모델을 양자화(Quantization)하여 사용할 수 있습니다.(제가 이렇게 많이 사용했습니다.) 그러나 성능은 많이 뒤쳐졌습니다.
그런데 1.5B 사이즈면 양자화하지 않고 사용해도 4o 성능 뺨친다는 것입니다.
이는 임베디드 시장에 AI에 돌풍을 예고하는 신호로 볼 수 있습니다.
Distillation을 어떻게 했는지 매우 궁금해지는 순간입니다…
심지어 OpenSource로 코드를 풀었기에 기존 LLM distillation 우회 방법이 아닌 내부 레이어의 weight를 직접 확인해서 KL-Divergence로 직접 Loss를 디자인 할 수 있다는 미친 가능성이 … ㅎㄷㄷ
전문용어들을 남발 했는데 결론은 미쳤다는 것입니다.
정리해보자면 딥싱크가 다른 모델들에 비해 성능이 월등히 뛰어난 것은 아닙니다.
새로운 기법을 활용해서 비슷한 수준으로 올렸다는 점에서 흥미로운 것입니다.
하지만 Distill모델들의 경우 새로운 경지를 보여주었습니다.
2. 딥씨크는 값싸게 학습했다?
Deepseek가 발표되고 나서 NDVIA의 주가가 삼성전자 2.3개가 사라졌습니다.

Deepseek가 화제가 많이 된 것이 값싼 GPU를 사용해서 성능을 GPT-o1과 유사하게 냈다는 점이었습니다.
Deepseek가 사용한 GPU는 H800입니다.
💡 NVIDIA GPU 종류NVIDIA는 GPU 아키텍쳐에 따라 A(Ampere) ⇒ H(Hopper) ⇒ B(Blackwell) 이라고 짓습니다.
(RTX 계열은 AI GPU가 아닌 게임, 디자인 을 위한 GPU입니다.)
각 아키텍쳐마다 100과 200이 있습니다.(A100, A200, H100, H200, B100, B200)
100은 base GPU를 의미하고 200은 base보다 더 성능이 뛰어난 GPU를 의미합니다.
DeepSeek에서 사용한 H800은 기존 판매용이 아닌 중국 수출용 제품입니다.
미국에서 중국을 견제하기 위해서 성능 좋은 GPU수출을 금지했습니다.
해당 조항을 지키면서 중국에 수출하기위해서 H100의 성능을 낮춘 H800을 만들어 수출 했습니다.
실제 논문의 표를 보면 2,788,000시간을 학습시켜 5.576M달러 비용이 들었다고 나와있습니다.
해당부분이 화재가 되어 뉴스에서도 최신 AI모델의 약 10분의 1비용으로 학습했다고 화재가 되었습니다.


하지만 이것은 거짓입니다.
위 표는 지금 화재가 되고 있는 DeepSeek-R1모델의 논문이 아닌 DeepSeek-V3모델의 논문 입니다.
또한 실제 논문에서 5.576M달러는 공식적인 훈련 비용만을 책정한 것이라고 나와있습니다.실제로 훈련에 필요한 데이터, 아키텍쳐, 알고리즘, 선행 연구 등에 든 비용은 제외된 것이라고 언급하고 있습니다.

R1모델은 V3모델을 베이스로 RL학습을 진행한 모델입니다.
RL을 공부해보면 SFT보다 훨씬 많은 리소스를 요구합니다.
NVIDIA 연구원 또한 이점을 꼬집어서 아래와 같은 트윗을 남겼습니다.

따라서 많은 언론에서 말한 5.576M달러로 학습했다는 것은 부정확합니다.
정확히 얼마가 들었는지 공개는 해주지 않았지만 post-Training부분은 비용이 pre-training에 비해 적게 드는 것은 사실입니다. 이를 감안했을 때 적은 비용은 맞지만 1/10 수준임은 부정확 수치입니다.
3. 더 이상 비싼 칩은 필요없다?

많은 기사들이 NDIVIA의 주가 추락의 원인이 더이상 최첨단 AI칩 없이 AI를 만들 수 있기 때문에 최첨단 AI칩을 사지 않을 것이다. 라는 예측을 합니다.
저는 이 예측이 잘못 됐다고 생각합니다.
첫 번째 이유로 DeepSeek도 NVIDIA의 CUDA생태계를 벗어난 것이 아닙니다.
무조건 NVIDIA를 사용해야 한다는 것입니다. DeepSeek로 인해 낮은 성능의 GPU로도 AI를 시도 할 수 있기에 중소기업에서도 AI를 시도할 수 있는 문을 열어준것입니다. 즉, GPU 수요가 오히려 증가했습니다.
두 번째 이유로 비싼칩이 더이상 안팔릴 것이다는 주장은 논문은 읽지 않은 사람들의 주장입니다.
DeepSeek-R1논문을 보면 재밌는 실험을 한 것이 있습니다.
”비싼 GPU로 학습한 AI를 Distill한 모델” VS “싼 GPU로 묵직하게 학습한 모델” 을 비교한 실험입니다.
실험 결과 비싼 GPU로 학습해서 Distill 한 모델이 압도적으로 성능이 높았습니다.

해당 논문에서도 “still require more powerful base models and large scale RL” 이라고 언급 되어 있습니다. 여전히 강력한 base model을 만들어야 하는데 그것을 위해 효율적인 scale law가 적용될 것이고 이를 효율적으로 학습 시켜줄 강력한 GPU가 요구 될 것입니다.
참고자료
DeepSeek-R1 알아보기
안녕하세요, 이번 포스팅에서는 DeepSeek에서 공개한 reasoning model, DeepSeek-R1의 기술 문서를 살펴보면서 과연 DeepSeek-R1은 어떤 모델인지 알아보는 시간을 가져보겠습니다. 중국의 기업 DeepSeek은 최근
foraidevelopers.com
'인공지능 역사와 이슈' 카테고리의 다른 글
| Grok-3 (0) | 2025.02.28 |
|---|---|
| 인공지능 기업 역사 : OpenAI (2) | 2025.02.27 |
| 인공지능 발전사 (with 핵심 모델) (0) | 2025.02.27 |
| 인공지능의 분야 (1) | 2025.02.27 |
| 튜링 테스트 (0) | 2025.02.27 |